Custom Identity Provider Trap: What We Should Have Built
A custom identity provider is a trap when you build commodity AuthN. The better path is an identity control plane.

Introduction
There is a seductive moment in every senior engineer's life where they look at OAuth2, OIDC, and SAML providers and think: "I could build a lighter version of this in a weekend."
For mykb-auth, that is exactly what we did. We built a fully functional custom identity provider. It handled user registration, secure password hashing, session management, JWT issuance, and internal key rotation. It was fast, lightweight, and we owned every line of code.
And then, despite it working, we made the decision to deprecate that version of it.
This is not a story about failing to build authentication. It is a story about recognizing the difference between a custom login system and an identity control plane.
The Prototype: The Illusion of Simplicity
We started with a clear goal: a zero-trust architecture for our AI-native knowledge base. We needed a system that could handle identity (who are you?) and detailed policy (what can you do?).
In three days, we spun up a custom service using FastAPI and SQLAlchemy. We implemented:
- AuthN: Bcrypt password hashing and JWT generation.
- AuthZ: A custom Policy Decision Point (PDP) for ABAC (Attribute-Based Access Control).
- Key rotation: An internal mechanism for rotating signing keys.
It felt like a win. We had eliminated the "bloat" of external providers. The service was small enough to understand, fast enough to run cheaply, and custom enough to match the product's policy model.
That is why this trap is dangerous. The prototype is not the hard part.
The hard part starts after the prototype works.
The Custom Identity Provider Build Trap
The code we wrote was not broken. The problem was not the code we had written. The problem was the code we had not written yet.
To make our custom IdP enterprise-ready, we were staring at a roadmap that had very little to do with our core product:
- MFA and passkeys: Essential for security, difficult to implement correctly, and unforgiving when edge cases appear.
- SCIM provisioning: Required for enterprise onboarding, offboarding, and group sync.
- Social logins: A maintenance loop across Google, GitHub, Microsoft, and whatever customers ask for next.
- Audit trails: Not just "user logged in," but admin actions, key changes, failed attempts, suspicious sessions, and tenant-level evidence.
- Security patching: Protection against timing attacks, token confusion, session fixation, dependency CVEs, and protocol mistakes forever.
"We successfully built a passport office. Then we realized our business was about building the secure facility behind the gates, not printing the ID cards."
That is the custom identity provider trap: authentication starts small, then becomes a permanent security program. Every feature you postpone becomes production risk once real users depend on the system.
The Pivot: Stop Building Login, Start Owning Policy
We realized we were conflating two distinct problems: Authentication and Authorization.
- Human authentication (AuthN) is a commodity. Verifying a user's identity through passwords, MFA, passkeys, sessions, and federation is a solved problem. It is high-risk and low-reward to reimplement from scratch.
- Authorization and machine identity are our domain. Deciding if User A can see Document B, if Host X can mint a token for Agent Y, or if Client Z can reach an MCP server is product logic.
The first belongs on a mature identity engine. The second belongs close to the product.
That split matters more in AI-native systems, because access control is no longer just "can this user open this page?" It becomes "which chunks can this model retrieve?", "which tools can this agent call?", "which tenant boundary applies to this generated answer?", and "what evidence do we need for audit?"
This is the same security posture behind our work on governed code execution for AI agents: the runtime may be flexible, but the policy boundary must be explicit.
The New Architecture
We moved to a hybrid model. The commodity identity layer moved onto Better Auth: sessions, users, organizations, passkeys, SSO, API keys, OAuth provider behavior, and JWT/JWKS mechanics. The product-owned layer stayed custom: machine bootstrap, MCP registry flows, token exchange, revocation, policy snapshots, and tenant-aware enforcement.
That distinction matters. We did not need to invent password hashing and session semantics. We did need a single control plane that could coordinate human users, host machines, agents, OAuth clients, MCP resources, and operator workflows from one boundary.
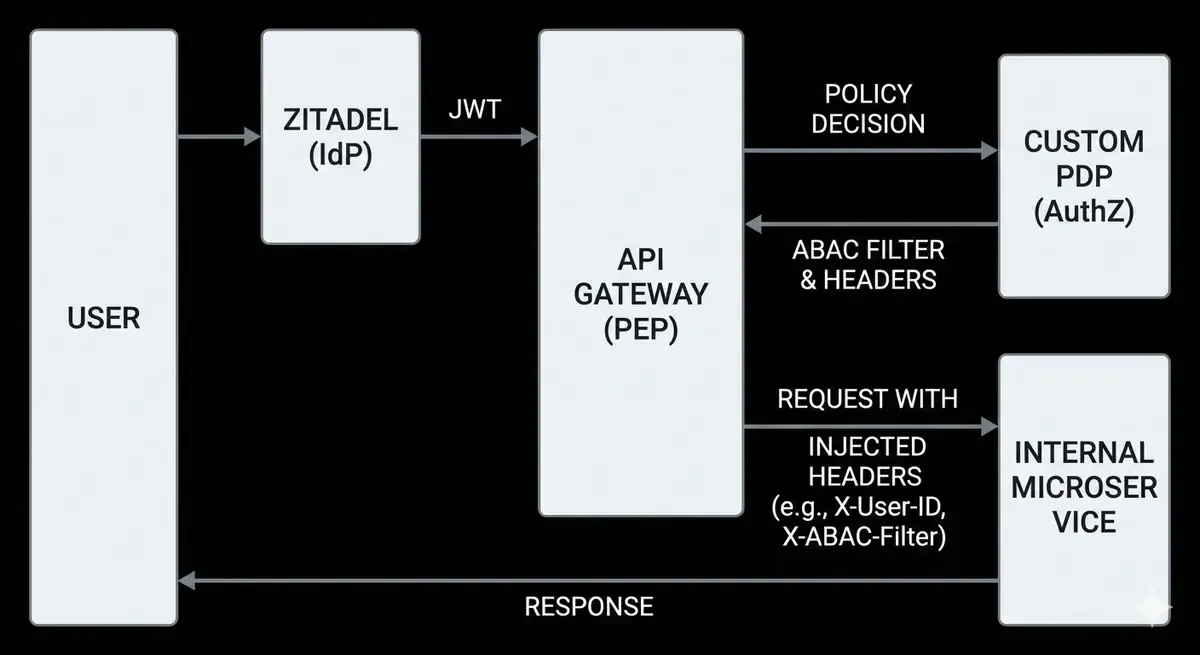
The Code: Zero-Trust Header Injection
The beauty of this shift is how it simplified our downstream services. Our gateway verifies the identity token, consults our internal PDP, and injects validated headers.
The internal microservices no longer worry about OAuth scopes or token parsing. They enforce the policy decision already made by the gateway:
@app.get("/api/documents")
async def get_documents(request: Request):
# The gateway has already authenticated the user and
# calculated the ABAC filter. We just enforce it.
user_id = request.headers.get("X-User-ID")
abac_filter_str = request.headers.get("X-ABAC-Filter")
abac_filter = json.loads(abac_filter_str)
return await db.find(abac_filter)The important part is not the header names. The important part is the trust boundary:
- The identity provider proves who the user is.
- The gateway verifies the token and applies policy.
- The PDP calculates the tenant-aware authorization decision.
- The downstream service receives a constrained request it can enforce locally.
That keeps authentication complexity out of every service while preserving product-specific access logic.
What We Kept and What We Deleted
The useful question was not "custom or vendor?" It was "which parts create product advantage?"
We deleted:
- hand-rolled password storage
- hand-rolled session issuance
- hand-rolled login flows
- hand-rolled user lifecycle primitives
- hand-rolled passkey and SSO plumbing
We kept:
- ABAC rules
- tenant-aware policy logic
- PDP/PEP boundaries
- audit shape for authorization decisions
- product-specific data filters
- machine registration invites
- OAuth client governance
- MCP registry and saved-token policy
- revocation streams and token-mint guardrails
That split gave us the best of both worlds: a mature identity engine for commodity identity work, and custom governance where the product actually needs judgment.
The Awkward Exception: Mono-Auth
Here is the awkward part: we eventually built Mono-Auth, a self-hosted identity control plane in Bun.
At first glance, that sounds like we walked straight back into the same trap. The difference is the boundary.
Mono-Auth is not a thin custom login service. It composes Better Auth with Hono, PostgreSQL, Redis, Connect RPC, and custom policy services. Better Auth handles the human identity substrate. Mono-Auth owns the parts that generic IdPs do not understand well enough for our system:
- host-machine bootstrap with invite JWTs
- confidential OAuth clients for machines and agents
- MCP server discovery and registry workflows
- org-scoped token governance
- revocation hints and streaming
- ID-JAG and token-exchange paths
- operator review flows for agent access
That is the line. A custom identity provider is a trap when it means "we wrote login because login looked easy." A custom identity control plane can be defensible when identity, machines, agents, tools, and policy all need to meet at one enforcement boundary.
The burden does not disappear. Mono-Auth still has to own production-grade security: CSRF, CORS, session limits, account lockout, token replay checks, key rotation, audit queues, rate limits, and revocation behavior. But that work is now attached to the actual product surface, not to a vanity reimplementation of commodity AuthN.
A custom identity control plane is about governance, not password hashing. Its goal is to coordinate machines, agents, and users under a unified security architecture.
When Custom Identity Infrastructure Might Still Make Sense
There are rare cases where building identity infrastructure is defensible.
You might need custom identity infrastructure if identity itself is the product, if machines and agents are first-class principals, if your system needs protocol behavior mainstream IdPs do not expose, or if your authorization model is inseparable from runtime governance. Even then, the bar should be high. You are not just building a login page. You are accepting a permanent security and compliance obligation.
Most product teams are not in that category.
For a normal SaaS system, the better architecture is usually:
- Use a mature identity engine for human AuthN.
- Keep authorization policy close to the product.
- Make the gateway the enforcement boundary.
- Preserve audit trails for policy decisions.
- Avoid leaking raw identity complexity into every microservice.
The pattern is especially useful when your product also has retrieval, automation, or agent execution layers. A knowledge system needs tenant-safe retrieval. An automation engine needs scoped tool access. A self-hosted agent stack needs clear runtime boundaries. Those concerns connect directly to the same principle: own the policy layer, not every commodity substrate underneath it.
For adjacent examples, see the schema-first LLM wiki architecture for tenant-aware knowledge systems and the Oracle Cloud AI agent setup for the infrastructure side of secure self-hosting.
A Practical Decision Checklist
Before building a custom identity provider, ask five questions:
- Will this help us ship a product capability customers can feel?
- Are we prepared to own MFA, passkeys, SCIM, audit logs, and protocol updates?
- Do we have security review capacity for token issuance, sessions, and key rotation?
- Can a mature IdP handle AuthN while our code owns AuthZ?
- What breaks if the engineer who wrote the IdP leaves?
If the answer points to "we just want less vendor friction," that is not enough. Vendor friction is annoying. Security ownership is permanent.
What Changed After the Delete
The architecture became easier to reason about after we removed the first custom identity provider.
Before the change, every authentication concern and every authorization concern lived too close together. A token bug could look like a policy bug. A session question could become an access-control question. The codebase had fewer vendors, but more conceptual coupling.
After the change, the boundary was cleaner:
- the identity engine owns human AuthN primitives
- the gateway owns token verification and policy handoff
- the PDP owns product-specific authorization decisions
- machine-identity services own host and agent lifecycle
- downstream services own local enforcement of already-scoped requests
That made reviews sharper. When a feature touched login, we knew it belonged near the IdP integration. When a feature touched tenant data access, we knew it belonged in the policy layer. The split reduced both code and ambiguity.
The real win was not only security coverage. It was operational focus. We stopped spending design time on commodity identity plumbing and started spending it on the access rules, machine principals, and runtime governance that actually define the product.
Conclusion
Dropping the first custom identity provider was not an admission of defeat. It was an act of architectural maturity.
By moving commodity AuthN onto a mature identity engine, we stopped carrying the wrong burden. By keeping our custom policy and machine-identity layers, we kept the flexibility to define complex, AI-driven access rules.
We stopped building the infrastructure that already exists so we could focus on the infrastructure that did not exist for us yet. In the end, the best code you write is often the code you delete before rebuilding the boundary correctly.